
0x00 引言
游戏AI和学术意义上的AI不同,后者尝试靠智能算法去优化或解决问题,而前者则是指在借助智能算法来改变NPC的思考和行为方式,从而让玩家感受到机器人的智能。本文将从几方面探讨游戏AI[1]:1)智能体的思考系统,包括有限状态机FSM、行为树与模糊逻辑等;2)智能体的感知系统,负责感知周围环境,并为思考和行动系统提供基础信息;3)智能体的行动系统,包括操控行为、A*寻路以及导航网络等;4)智能体的战略系统,即群集行为。
游戏中的AI角色行为一直处于感知-思考-行动的无限循环之中。本文主要研究智能体的行动系统,原文的游戏引擎采用unity3D,这里不介绍代码,代码请看原文献。智能体AI架构如下图所示:
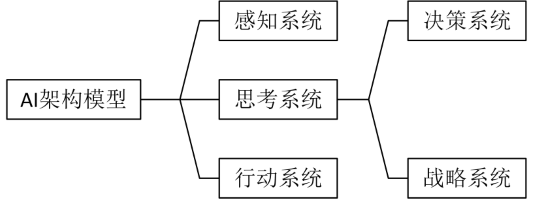
0x01 智能体操控行为
操控行为就像赋予智能体自主行动能力一样,使其按照一定的逻辑规则[2]来运动,这种行为的感知类似于真实的生物,是有范围且较小的。而A*寻路则是一种寻找最优解的方法,前提是对个体来说,在个体与目标之间的路况是全部已知的,目的是寻找最短路径并避开障碍物,最后到达目标。对于仿真大型群体,前者效率更高,且行为更真实和优美。而在仿真少量个体行为时,后者更具即使策略意义。
1 | 1 个体行为操控 |
1、个体行为操控
1.1、靠近与离开
靠近过程是指给智能体一个理想情况下指向目标的预期速度向量,并施加力,实时改变速度至预期速度向量。而离开过程恰恰相反,是指给智能体一个理想情况下远离目标的预期速度向量。二者的具体过程看下图:
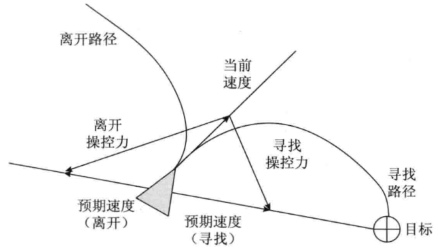
从图中可见,靠近(寻找)的预期速度向量为当前速度向量与靠近(寻找)遥控力向量之差,其变化速度可在操控力向量前加系数。而离开的预期速度向量为当前速度向量与离开遥控力向量之差。
1.2、抵达
抵达行为与靠近的差别在于,前者的预期速度向量将随着智能体与目标之间的距离而改变,并且可是设置减速半径,当智能体在半径之外,便采取靠近的全速模式,当在半径内时,速度随距离减小而减小至零。
1.3、追逐与逃避
追逐与靠近的不同点是目标为移动物体,为了达到追逐的目的,需要分两种情况:1)目标运动的速度方向与智能体速度方向夹角小于20°,这种情况下直接采取靠近算法;2)夹角大于20°,这种情况下说明智能体并不是面对目标,所以要像猎豹追鹿一样预测时间T之后的目标位置,并对预测点采取靠近算法,如下左图所示:
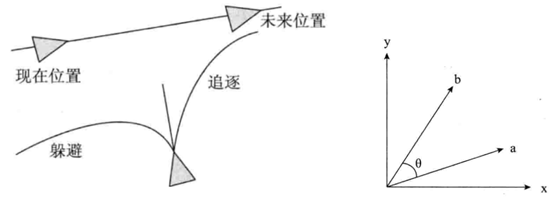
该预测时间T设定为与两者距离成正比,与两者速度成反比。夹角的计算方法,如上右图,可采用两个单位向量的点积求解。
逃避过程相对简单,不用像追逐一样考虑两种情况,只需要预测追逐者时间T之后的位置,该预测时间可设定为常数,或者与两者距离成正比(当然不应该去设置与速度之间成反比,这样子怕是永远追不上?)。
1.4、随机徘徊
随机徘徊是让智能体产生有真实感的随机移动,比如巡逻的士兵与惬意吃草的牛羊。如果使用隔时间分配任意目标点的方法,会使行为看起来不真实,类似会突然掉头。Craig Reynolds[3]在1999年发表的一篇文献解决了该问题,他采用左下图所示方法,在一个圆周上生成目标点,且随时间更新位置,智能体采用靠近算法接近目标,当达到位置时重新生成圆周并反复该过程。最终生成由下图所示行动轨迹。
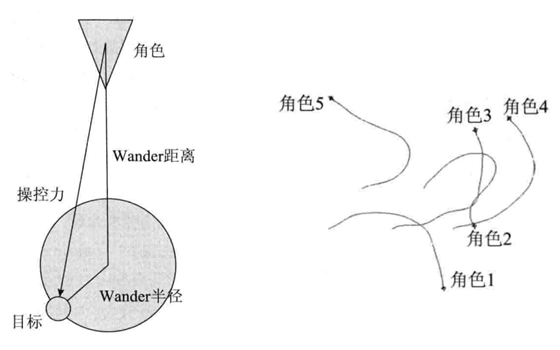
1.5、路径跟随
路径跟随常常会用在赛车游戏中,它需要智能体按照某条指定路径运动,最简单的实现方法就是在一条路径上选取路点,让智能体做靠近算法,达到一个路点再朝向下一个。为了增加运动的平滑与多变,这里引入路点的半径,即当智能体接触到半径,就当作其已经到达该路点。如下图所示,不同的路点半径会导致运动过程变化。
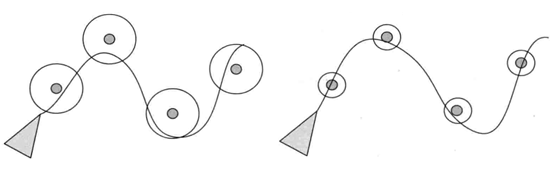
1.6、避开障碍
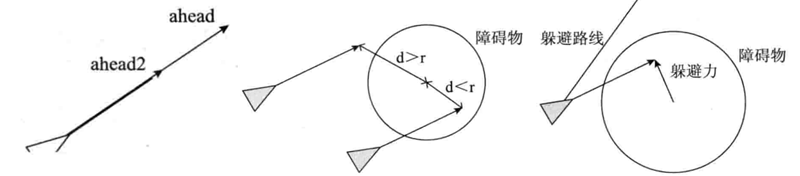
智能体在朝着目标方向移动的时候,可能会在路上遇到障碍物,如果没有察觉到就会产生碰撞,为了躲避障碍物,我们在智能体速度方向上添加两个向量ahead、ahead2,如左下图所示。当任何一个向量在障碍物半径内时,都会给智能体施加一个如由下图所示的躲避力。至于为什么加两个视觉向量的原因,是当智能体的远视角开始躲避障碍物时,近视角可能会碰到另一个障碍物,那么躲避优先级就改变为更近的障碍物。
2、群体行为操控
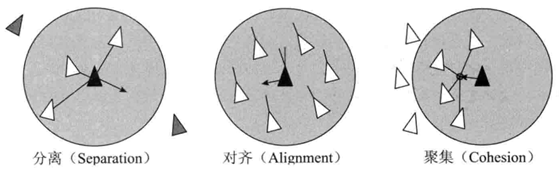
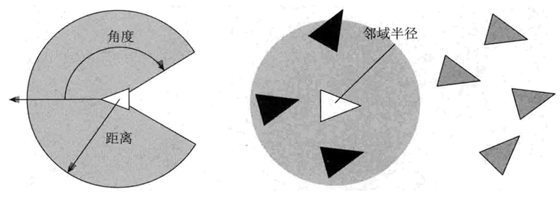
相比与A*寻路,操控行为最大的优势就是在做群体行为操控时展现出的真实感。在研究相关算法之前,先引入两个先导知识[3]:1)组行为。是指群体中的个体之间相互交互的一些操控力规则,主要有分离、队列和聚集三种行为。2)雷达。个体要实现决定使用哪些操控力的前提是检测附近的AI角色,这种侦测行为与雷达相似。
2.1、分离
分离就是避免个体在局部过于拥挤而产生的操控力,如上图所示黑色三角形所表示的智能体通过雷达扫描附近有三个白三角表示的邻居,先求出某个邻居对智能体的排斥力方向单位向量,即$\frac{r}{\left | r \right |}$,而排斥力的大小与距离成反比,因此排斥力应为$\frac{r}{\left | r \right | ^{2}}$,最后将所有邻居的操控力相加即为总的分离操控力。
2.2、队列
队列就是朝向附近同伴平均朝向的操控力,图中显示黑色三角形头部的灰线为其当前速度,黑线代表所有邻居速度方向的平均值,则队列操控力即为黑线与灰线的插值向量。
**2.3、聚集**
聚集就是向附近同伴的平均位置移动的操控力,图中四个邻居连接的黑点即为他们的平均值,从智能体指向黑色小点的向量即为聚集操控力。
0x02 A星寻路
寻找最优路径是让智能体显得更聪明的方法,A*寻路就是一种寻找最短路径并避开障碍物的算法,相比于操控行为,需要提前知道地图上的各个节点以及每个点的代价值,占用cpu强度大,因此更适合于控制少量且高智商的智能体。
1 | 1 导航图网格划分方式 |
1、导航图网格划分方式
A*寻路网格划分方式通常有3种:基于单元的导航图、基于可视点的导航图与导航网格。现在的游戏中,广泛使用的方式是利用导航网格寻路,再靠设计师手工放置躲藏点、埋伏点进行战术决策。此三种导航图划分如下图:

1.1、单元导航图
这种方法是将游戏地图划分为多个正方形或六边形单元组成的规则网络。如果划分格数过大会导致难得到好的路径,格数过小则需要储存大量节点,且影响cpu效率。并不算是一种很好的分割方法。
1.2、可视点导航图
可视点导航图又称路点图,是依靠场景设计者在场景中手动设置一些两点之间可见的路径点(不可见的话,就可能会跨障碍物,这样的路径是不可选取的)。这种方法的优点是灵活性强,场景设计者可根据自己的想法选择掩护、伏击位置,同时增加相应的位置信息(与路径代价相关的位置信息,在选择路径时要用到)。这种方法的缺点是:1)手工放置路径点很繁琐。尤其是在地图巨大的情况下;2)难以表示出实际的二维行走区域。如图中所示标的点位通常在墙边缘,而实际行走应该是在路中央;3)存在严重的组合爆炸问题。由于是人工布置点,因此点数无法控制精确,大量的点位将导致路径组合数爆炸。
综上所述,场景设计师通常依靠可视点导航图来手工放置躲藏点、埋伏点等特殊点位进行战术决策。
1.3、导航网络
导航网络用多边形来分割场景,从图中可以观察到,此种方法分割的路径点数量远远少于单元导航图,且路径点为各多边形的中心点,这将大大减轻cpu的压力。使用这种分割方法要注意的是,如果智能体完全按照路径点来行走,如图中灰线所示就显得很笨拙,人的真实行为应当是类似于黑线所示,这类问题称为路径的平滑,unity3D的A* Pathfinding Project已经包含了相关的后处理功能。
综上所述,场景设计师通常使用这种方法来分割场景,但其缺点是生成导航网格需要较长时间。
2、A星寻路算法
A星寻路算法即一种使智能体寻找最短路径并避开障碍物的算法,先引入四个术语:1)代价。代价是在寻路过程中节点之间的消耗值,由设计师定义,例如时间、能量、金钱等等。2)目标估计。由于从当前节点到目标节点的代价无法计算(因为路径未知),则需要一种算法来估算该代价值,比如单元导航图就可以计算两节点之间的相对(x+y)值;3)节点属性。在A星算法中,每个节点都必须包含3个属性值,分别是g-从起始节点到当前节点的总代价,h-目标估计,f=g+h。4)Open表与Closed表。前者所记录的节点表示已经计算节点属性且没被单独拿出来计算其周围所有单元节点属性的节点,而后者记录的节点表示已经计算节点属性且已经被单独拿出来计算其周围所有单元节点属性的节点。A星算法具体运作过程如下gif图所示:

A星寻路算法的具体流程如下:1)计算起始点的节点属性,并将其归入Open表;2)计算起始点附近所有单元节点属性,并将起始点归入Closed表,邻近点归入Open表;3)从邻近点搜索f值最小的点,并重复1、2两条过程。假如Open表内节点的属性值改变且比原值小,则覆盖之且重新更新运动箭头;4)从所有Open表节点中寻找f值最小的点,并无限重复1、2、4三条过程,直到终止点被加入Open表。假如Open表内节点的属性值改变且比原值小,则覆盖之且重新更新运动箭头;5)导出运动箭头记录的最优路径。
实际上A星寻路算法与人类择优过程很类似,我们总是能算未来几步路,并据此选择当前情况下最优的方案,但由于我们以为自己与目标之间一马平川,所以有许多障碍离得太远也就忽视了,当我们碰壁失败了,才会总结出这条路不通的结论,于是我们就更新观念,认为当初应该选择哪条路将更快,这时就更新了那条初始道路的节点属性,如此往复循环,最后我们能够明白哪条路才是真正的最优解。虽然这种方法看起来很笨,但是在未知障碍的情况下应该算是较好的策略了。
0x03 引用文献
[1]unity3D人工智能编程精粹
[2]https://www.researchgate.net/profile/Craig_Reynolds2/publication/2797343_Flocks_Herds_and_Schools_A_Distributed_Behavioral_Model
[3]http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.86.636&rep=rep1&type=pdf