
0x00 引言
本文主要知识结构与素材摘自《基于深度学习的计算机视觉》[1]。
计算机视觉当前主要研究领域如下图所示:
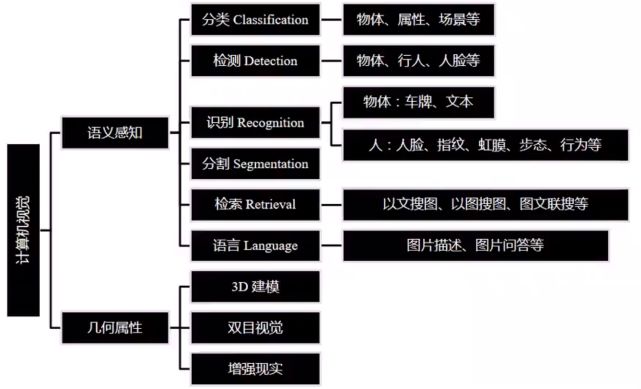
在经过图像分割得到图像内各个物体的标签之后,需要对物体之间的关系做出描述,即图像描述(图说)。
0x01 深度语言模型
1 | 1 递归神经网络RNN |
1、递归神经网络RNN
RNN包括两类,分别是时间递归神经网络(Recurrent Neural Network)和结构递归神经网络(Recursive Neural Network),常用的是前者。
1.1、时序后向传播(BPTT)
RNN其优化算法采用时序后向传播(BPTT),是传统后向传播(BP)在时间序列上的扩展。
1.2、朴素Vanilla-RNN
这种网络,其$t-1$时刻的隐层状态会参与t时刻输出的计算,但是具有严重的梯度消失问题。
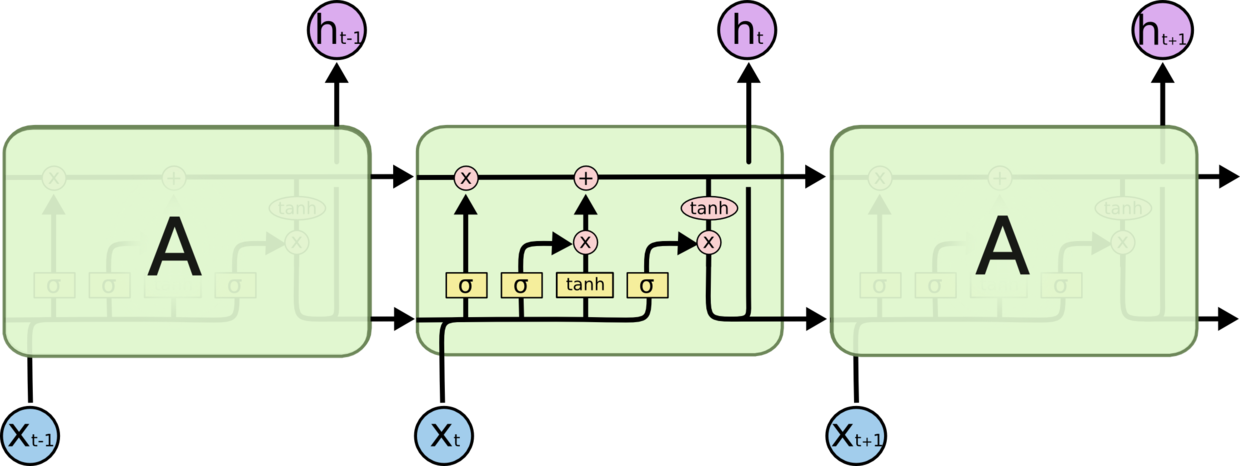
*2、LSTM长短时记忆模型
能够有效捕捉长时记忆,其有1个记忆神经元和3个控制门神经元,分别是输入门、忘记门以及输出门。LSTM记忆原理可阅读博文[2],其结构图如下图所示:
3、LSTM变种
其变种有Peephole与Coupled忘记-输入门。
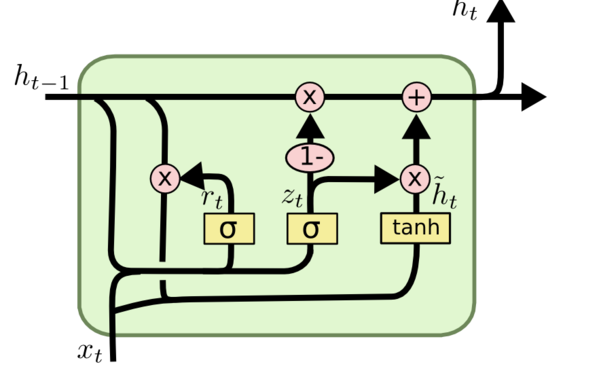
*4、GRU门限递归单元
2014年提出的GRU门限递归单元(Gated Recurrent Unit)为精简版的LSTM。相比于LSTM其有两个改动,其一合并了输入门和忘记门,其二合并记忆状态和隐藏状态。其包含两个控制门,分别是重置门和更新门。GRU的结构图如下所示:
比较LSTM与GRU两种模型,LSTM有如下特点:
1)模型复杂,参数多,拟合能力强
2)数据要求:大规模、复杂度高
GRU有如下特点:
1)模型精简,参数少,拟合能力相对弱
2)适用于偏小规模、不是很复杂的数据
0x02 图说模型
所谓图说模型就是输入一张图片,并输出客观描述图片内容的句子。
该过程是将视觉内容转化为语言内容,传统的计算机视觉(CV)是对图片的理解,而现在自然语言处理领域(NLP)是对语言的理解。
1 | 1 简介 |
1、简介
传统的分段处理策略流程为:
1)图片内容->文本标签
2)文本标签->描述语句
其优势是能够滤除干扰信息,模块化的结构以及直接使用CV与NLP研究成果,但是劣势是第一步的错误判断会影响第二布的语言推理。
新的点对点策略流程为:
1)将图片(利用CNN)与文本(利用one-hot)映射到同一共享空间下
2)图片特征->语言描述
其优势是图片与文本能同时训练,劣势是黑箱严重。
2、DNN框架
点对点策略就是DNN框架,其包含了三个部分:
1)CNN:图片理解。比如VGG、ResNet、GoogLeNet
2)RNN:语言理解及生成。比如LSTM、GRU
3)特殊功能模块。Attention
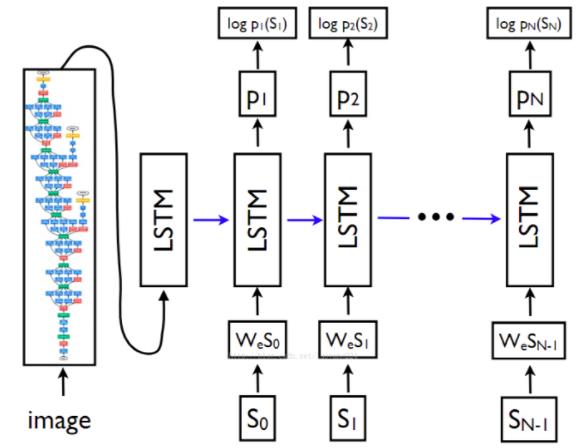
2.1、Show and tell模型
最简单的模型,其组成部分为CNN+LSTM,其结构如下图所示:
2.2、Show,attend and tell(SAT)模型
其组成部分为CNN+LSTM+Attention模块(注意机制),即增加了一个注意力机制。
0x03 引用文献
[1]http://www.chinahadoop.cn/course/916
[2]https://blog.csdn.net/u011746554/article/details/75005139