
0x00 引言
本文主要知识结构与素材摘自《基于深度学习的计算机视觉》[1]。
计算机视觉当前主要研究领域如下图所示:
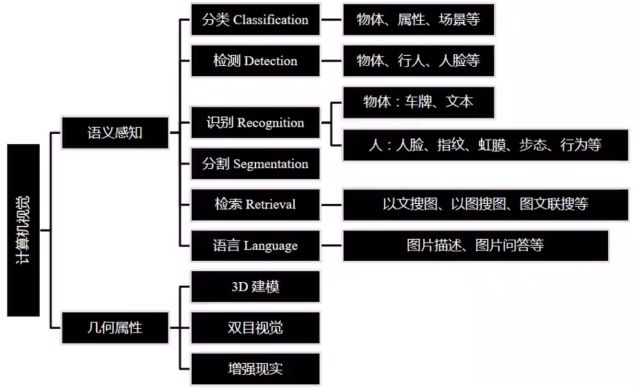
在经过图像数据处理以及获得图像的特征以及经过图像识别以后,就需要利用这些前期得到的信息基础来完成不同的计算机视觉任务,本文将涉及图像分割的内容。
0x01 显著性检测
显著性检测关注两类问题。其一显著性物体分割,即最能引起人的视觉注意的物体区域。其二注视点预测,即通过对眼动的预测和研究探索人类视觉注意机制。
视觉注意机制又有两种策略。其一自底而上基于数据驱动的注意机制,即从数据出发的颜色、亮度、边缘等特征。其二是自上而下基于任务驱动的注意机制,即从知识、预期、兴趣等认知因素出发。
显著性检测常采用由VGG网络修改而成的DNN模型。
0x02 图像分割之物体分割
1 | 1 前景背景分割 |
1、前景背景分割
将含有背景的前景物体分割出来,需要交互提供初始标记。
1.1、Graph Cuts分割
是一种基于图论的分割方法,具体内容看博文[2]。
1.2、GrabCut分割
此种算法第一步使用标记初始化颜色模型,第二步迭代进行Graph Cuts分割算法。
0x03 图像分割之语义分割
不但要做一张图片上的物体分割,且要理解、识别各个物体的内容。
语义分割的用处有机器人视觉和场景理解、辅助/自动驾驶、医学X光等。
在2015年之前的语义分割用的算法是手工特征+图模型(CRF)。从2015年开始,便运用深度神经网络模型:
1)改进的CNN。传统CNN存在一些问题。
2)全卷积网络/FCN(Fully Convolutional Networks)。所有层都是卷积层,能够解决降采样后的低分辨率问题。
1 | 1 全卷积网络/FCN |
1、全卷积网络
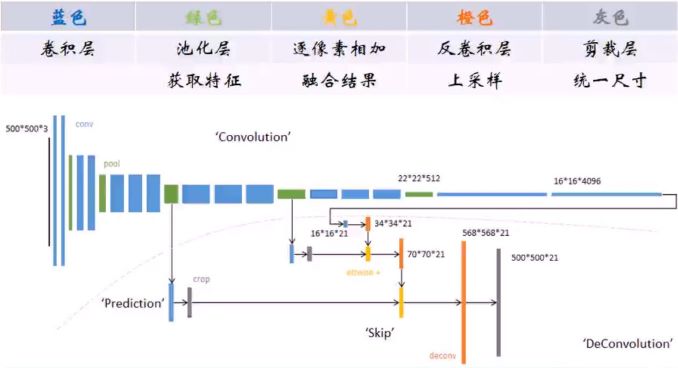
全卷积网络具有三个重要的操作:
1)卷积化。即将所有的全连接层转换成卷积层,适应任意的尺寸输入,并输出低分辨率的图片。
2)反卷积。将低分辨率的图片进行上采样,输出同分辨率的分割图片。
3)跳层结构。精化分割图片。
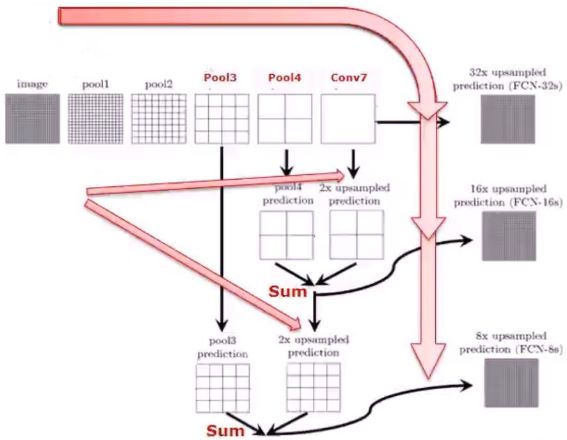
全卷积网络的构架图例如下所示:
1.1、卷积化
即卷积层,具体看计算机视觉-图像识别[3]。
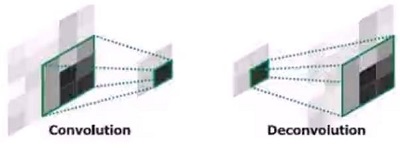
*1.2、反卷积
所谓反卷积(转置卷积)就是卷积的逆操作,反卷积核是卷积核的转置,其过程如下图所示:
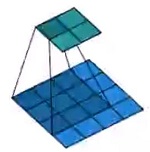
有必要细致地解释一下卷积以及反卷积的矩阵化写法。有如下所示4$\times $4的图像,需要卷积为2$\times $2的输出:
则每个卷积核都可以写为如下图所示的一行,合并成一个矩阵C,输入量为图像的16个元素展开成一个列向量x,输出为一个包含四个元素的列向量y,卷积过程可以用公式$y=Cx$表示。

则每个反卷积核则可用公式$y=C^{T}x$表示。
还有一种反池化操作(据说用的不多),每次均要记录池化时的位置,其过程如下图所示:

1.3、跳层结构
即将当前卷积层与前两层卷积层的输出做融合。这样做的原因是直接使用32倍反卷积得到的分割结果过于粗糙。
2、DeepLab全卷积网络
由于反卷积存在一定的缺陷,比如不能完全恢复信息。现在常用的网络为DeepLab全卷积网络。其基本结构为优化后的DCNN+传统的CRF图模型。
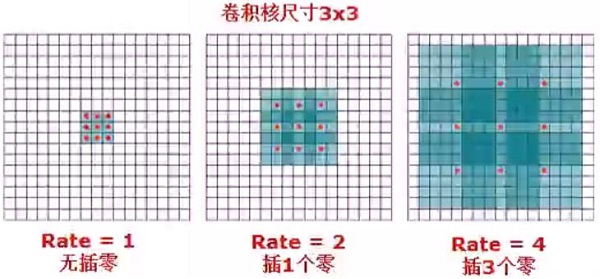
*2.1、DCNN-孔算法
解决了原始FCN网络的输出低分辨率问题,能够灵活控制分辨率。其正式名称为膨胀卷积,取代上采样反卷积。其rate值越大,感受野越大,所谓rate即在卷积核元素之间插入步长,如下图所示:
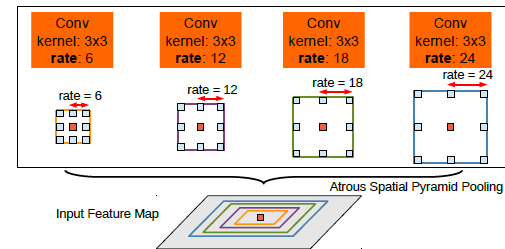
2.2、DCNN-Atrous空间金字塔池化
在第六层并行引入4个不同rate的膨胀卷积,能够解决物体在多尺度图像中状态不同的问题,其过程如下图所示:
2.3、全连接CRF
其作用是通过迭代精化分割结果(恢复精确边界)。
0x04 引用文献
[1]http://www.chinahadoop.cn/course/916
[2]https://www.cnblogs.com/hjlweilong/p/6119822.html
[3]https://jailbreakfox.github.io/2018/12/30/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89-%E5%9B%BE%E5%83%8F%E8%AF%86%E5%88%AB/